

More from iWeb Scraping Services


Related Blogs


Archives
Social Share
How Python And BeautifulSoup Are Used To Scrape Hotel Listings From Booking.Com?
Body
Scraping hotel listings from numerous websites is one of the most common uses of Web Scraping Services. This might be done by keeping an eye on rates, creating an aggregator, or improving the user experience on existing hotel booking services.
This can be accomplished with the help of a simple script. We'll utilize BeautifulSoup to assist us to extract data, and we'll use Booking.com to find hotel information.
To begin, we'll need these lines of code to retrieve the Booking.com search results page and set up BeautifulSoup to assist us query the page for meaningful data using CSS selectors.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.booking.com/searchresults.html?label=gen173nr-1FCAEoggI46AdIM1gEaGyIAQGYATG4AQfIAQzYAQHoAQH4AQKIAgGoAgO4AvTIm_IFwAIB;sid=7101b3fb6caa095b7b974488df1521d2;city=-2109472;from_idr=1&;dr_ps=IDR;ilp=1;d_dcp=1'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
To avoid being blacklisted, we also pass the user agent headers to simulate a browser call.
Now let's look at the Booking.com search engine results for a certain destination. This is how it appears to be.
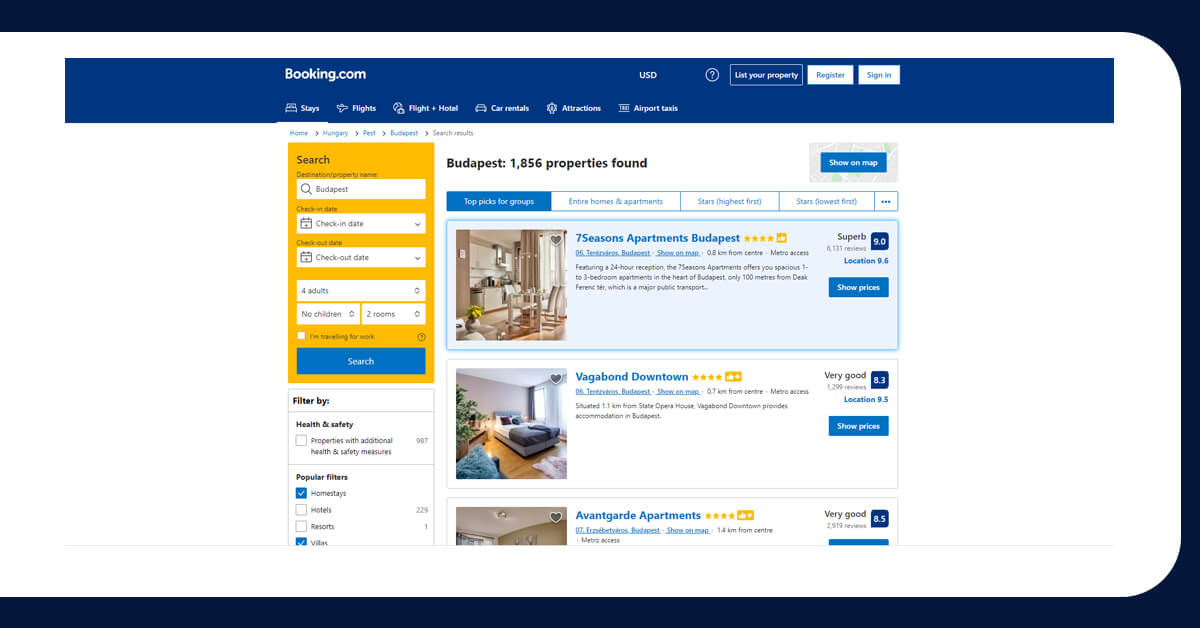
When we examine the page, we notice that each item's HTML is contained within a tag with the class sr_property_block.
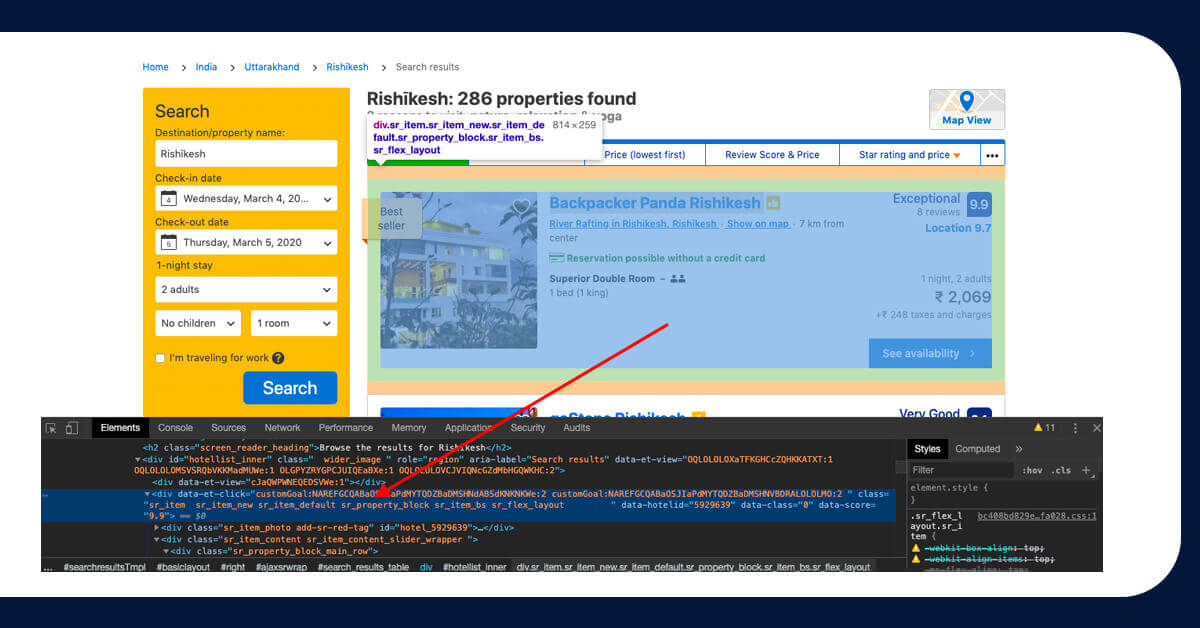
We could simply use this to divide the Html page into these pieces, each of which has information about a single object, such as this:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.booking.com/searchresults.html?label=gen173nr-1FCAEoggI46AdIM1gEaGyIAQGYATG4AQfIAQzYAQHoAQH4AQKIAgGoAgO4AvTIm_IFwAIB&sid=eae1a774e77c394c5e69703d37e033a3&sb=1&src=searchresults&src_elem=sb&error_url=https://www.booking.com/searchresults.html?label=gen173nr-1FCAEoggI46AdIM1gEaGyIAQGYATG4AQfIAQzYAQHoAQH4AQKIAgGoAgO4AvTIm_IFwAIB;sid=eae1a774e77c394c5e69703d37e033a3;tmpl=searchresults;city=-2109472;class_interval=1;dest_id=-2109472;dest_type=city;dr_ps=IDR;dtdisc=0;from_idr=1;ilp=1;inac=0;index_postcard=0;label_click=undef;offset=0;postcard=0;room1=A%2CA;sb_price_type=total;shw_aparth=1;slp_r_match=0;srpvid=7df1609ef03a0103;ss_all=0;ssb=empty;sshis=0;top_ufis=1&;&sr_autoscroll=1&ss=Rishīkesh&is_ski_area=0&ssne=Rishīkesh&ssne_untouched=Rishīkesh&city=-2109472&checkin_year=2020&checkin_month=3&checkin_monthday=4&checkout_year=2020&checkout_month=3&checkout_monthday=5&group_adults=2&group_children=0&no_rooms=1&from_sf=1'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
#print(soup.select('.a-carousel-card')[0].get_text())
for item in soup.select('.sr_property_block'):
try:
print('----------------------------------------')
print('----------------------------------------')
except Exception as e:
#raise e
print('')
When you execute it
python3 scrapeBooking.py
The card will isolate the cards HTML
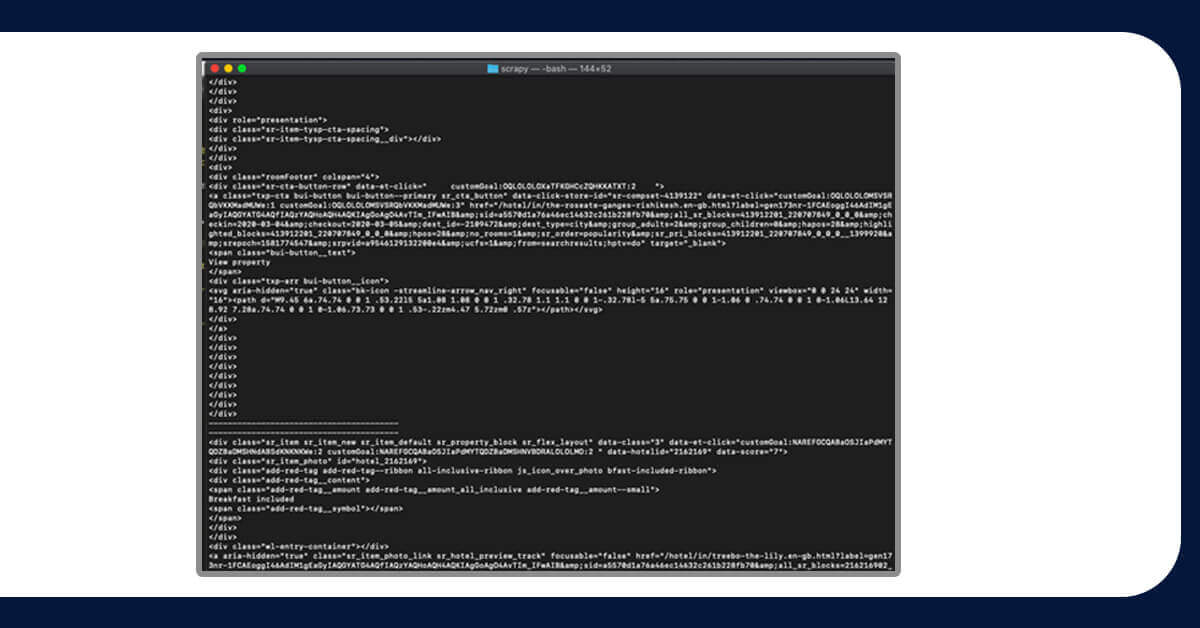
On closer inspection, you'll notice that the hotel's name is always preceded by the sr-hotel_name_class... While we're at it, let's obtain the number of reviews, pricing, and ratings.
for item in soup.select('.sr_property_block'):
try:
print('----------------------------------------')
print(item.select('.sr-hotel__name')[0].get_text().strip())
print(item.select('.hotel_name_link')[0]['href'])
print(item.select('.bui-review-score__badge')[0].get_text().strip())
print(item.select('.bui-review-score__text')[0].get_text().strip())
print(item.select('.bui-review-score__title')[0].get_text().strip())
print(item.select('.hotel_image')[0]['data-highres'])
print(item.select('.bui-price-display__value')[0].get_text().strip())
We also attempted to obtain the hotel image and link, as well as other critical pieces of information.
This is how the entire code appears.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.booking.com/searchresults.html?label=gen173nr-1FCAEoggI46AdIM1gEaGyIAQGYATG4AQfIAQzYAQHoAQH4AQKIAgGoAgO4AvTIm_IFwAIB&sid=eae1a774e77c394c5e69703d37e033a3&sb=1&src=searchresults&src_elem=sb&error_url=https://www.booking.com/searchresults.html?label=gen173nr-1FCAEoggI46AdIM1gEaGyIAQGYATG4AQfIAQzYAQHoAQH4AQKIAgGoAgO4AvTIm_IFwAIB;sid=eae1a774e77c394c5e69703d37e033a3;tmpl=searchresults;city=-2109472;class_interval=1;dest_id=-2109472;dest_type=city;dr_ps=IDR;dtdisc=0;from_idr=1;ilp=1;inac=0;index_postcard=0;label_click=undef;offset=0;postcard=0;room1=A%2CA;sb_price_type=total;shw_aparth=1;slp_r_match=0;srpvid=7df1609ef03a0103;ss_all=0;ssb=empty;sshis=0;top_ufis=1&;&sr_autoscroll=1&ss=Rishīkesh&is_ski_area=0&ssne=Rishīkesh&ssne_untouched=Rishīkesh&city=-2109472&checkin_year=2020&checkin_month=3&checkin_monthday=4&checkout_year=2020&checkout_month=3&checkout_monthday=5&group_adults=2&group_children=0&no_rooms=1&from_sf=1'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
#print(soup.select('.a-carousel-card')[0].get_text())
for item in soup.select('.sr_property_block'):
try:
print('----------------------------------------')
print(item.select('.sr-hotel__name')[0].get_text().strip())
print(item.select('.hotel_name_link')[0]['href'])
print(item.select('.bui-review-score__badge')[0].get_text().strip())
print(item.select('.bui-review-score__text')[0].get_text().strip())
print(item.select('.bui-review-score__title')[0].get_text().strip())
print(item.select('.hotel_image')[0]['data-highres'])
print(item.select('.bui-price-display__value')[0].get_text().strip())
print('----------------------------------------')
except Exception as e:
#raise e
print('')
When you execute the code
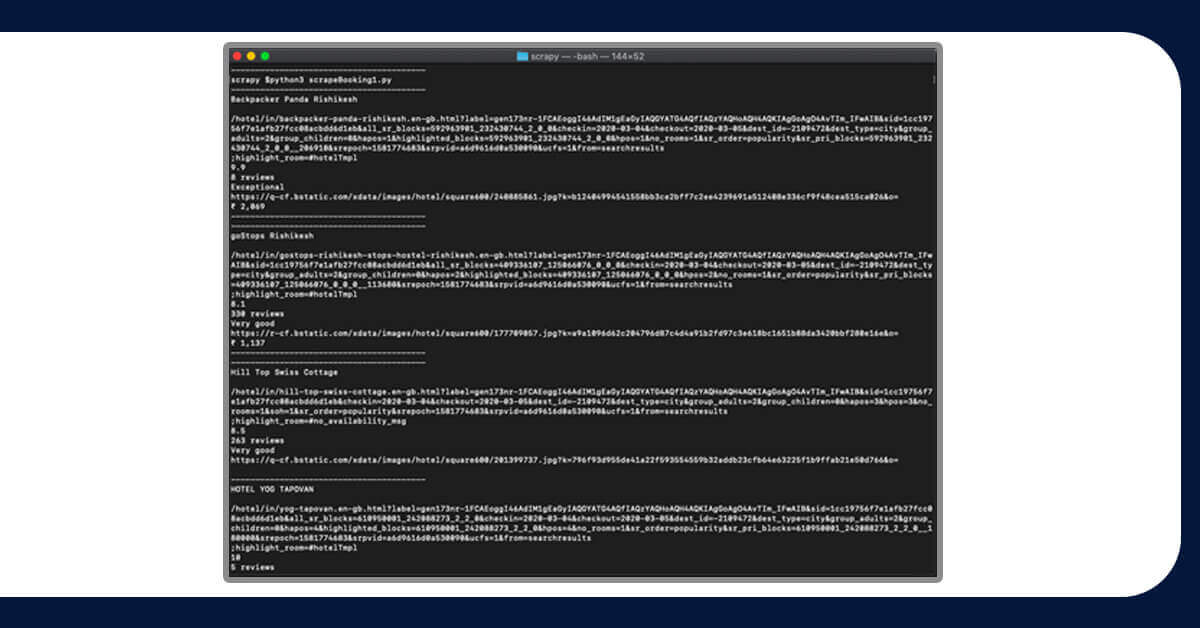
This provides all the information we require.
Overcoming IP Blocks
Participating in a personal rotating proxy service such as Proxies API can often mean the difference between a successful and pain-free web scraping operation that consistently gets the job done and one that never does.
Plus, with both the current offer of 1000 free API requests, there's absolutely nothing to lose by comparing notes while using our rotating proxy. It simply takes a single line of integration to make it almost unnoticeable.
Our rotational proxy server Proxies API is a simple API that instantly solves any IP Blocking issues.
There are millions of high-speed spinning proxies scattered over the globe.
With our IP rotation service, you can rest assured that your IP address will be changed
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API using our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions) and our automatic CAPTCHA cracking technology.
In any programming language, a basic API like the one below can be used to access the entire system.
curl "http://api.iwebscraping.com/?key=API_KEY&url=https://example.com"
For more details, contact iWeb Scraping, today!!!



Comments